
Tartalom
- Bevezető
- Teszt fájl készítése
- Ellenőrző összeg generálása
- Ellenőrző összeg tárolása
- Tárolt ellenőrző összeg felhasználása ellenőrzés céljából
- Egyszerre több ellenőrző összeg tárolása egy md5 fájlban
- Egyszerre több fájl ellenőrzése egy md5 fájl segítségével
- Megváltozott tartalmú fájl ellenőrzése
- Csak a hibás fájlok megjelenítése az ellenőrzés során
- Fájl útvonalak kezelése
- Fájlok kiinduló összegzési értékeinek kötegelt felvitele egy md5 fájlba
- Eredmények script-ekben történő felhasználása
- Bináris és szöveges módú fájlbeolvasás
- Konklúzió
Bevezető
Az md5sum parancs egy olyan eszköz, amely lehetővé teszi fájlok MD5 (Message Digest Algorithm 5) összegzési értékének kiszámítását és ellenőrzését. Az MD5 egy egyirányú hash függvény, amely egy bemeneti adatsorból egy rögzített hosszúságú, 128 bites (32 hexadecimális karakter) összegzést hoz létre. Ezt az összegzést gyakran használják fájlok integritásának ellenőrzésére, mivel még egy apró változás a fájlban is teljesen másik hash értéket eredményez.
Ebben a leírásban áttekintjük az md5sum parancs alapvető használatát Debian rendszeren.
Teszt fájl készítése
Első körben készítünk egy teszt fájlt, amivel kipróbálhatjuk az md5sum parancsot. Ehhez az echo parancs segítségével beleteszünk egy teljes "Lorem Ipsum" bekezdést egy szöveges fájlba:
echo "Lorem ipsum ..." > test.txt

Természetesen bármilyen bináris fájlt is használhatunk az md5sum parancshoz, itt csak a példa kedvéért hoztam létre egy szöveges fájlt.
Ellenőrző összeg generálása
A fájlok ellenőrző összegének generálásához használjuk az alábbi md5sum szintaxist:
md5sum test.txt

Ekkor kiírja a 32 hexadecimális karakterből álló ellenőrző összeget és a fájl nevét:
0d0ebce12145deceef5ec3ab8fdc6e86 test.txt
Ellenőrző összeg tárolása
A generált ellenőrző összeget és a forrás fájl nevét eltárolhatjuk egy tetszőleges szöveges fájlban is, amit később fel tudunk használni ellenőrzés céljából:
md5sum test.txt > tests.md5

Tárolt ellenőrző összeg felhasználása ellenőrzés céljából
Ha később ellenőrizni szeretnénk a fájlunk "eredetiségét", mert például mondjuk mások is dolgoznak a fájlunkkal, és biztosak szeretnénk lenni benne, hogy nem módosult a tartalma, akkor használjuk a -c kapcsolót:
md5sum -c tests.md5

Ilyenkor az md5sum parancs ismét leellenőrzi a fájlban lévő fájlneve(ke)t, és összehasonlítja a nevek előtt korábban eltárolt ellenőrző összegekkel. Ha rendben van a fájl, akkor a fájl nevet és utána az "OK" jelzést kapjuk.
Egyszerre több ellenőrző összeg tárolása egy md5 fájlban
Egy md5 ellenőrző fájlban lehetőség van akárhány ellenőrző összeg és fájlnév társítást tárolni, csak mindegyiket új sorban kell megadni.
További tesztfájlok létrehozása
A példa kedvéért generálunk két újabb teszt fájlt, mindegyiket más módszerrel készítjük el.
Az elsőt a dd parancs segítségével hozzuk létre úgy, hogy kimásolunk egy adott mennyiségű byte-ot a /dev/urandom eszközből:
dd if=/dev/urandom of=test2.bin bs=256 count=1 status=none

A példában ki is listáztam a fájlt, ahol jól látható a fájl 256 byte-os hossza. Mivel a /dev/urandom eszközből bármilyen byte érkezhet, ezért ezt a fájlt .bin kiterjesztéssel láttam el, ezzel jelezve hogy a fájlban bináris adat van. Utána pedig le is kértem az md5sum paranccsal ennek az új fájlnak az ellenőrző összegét is, csak hogy láthassuk kiírva is.
A másik tesztfájlt pedig a head és a tr parancsok segítségével hozzuk létre ugyanakkora byte méretben, és szintén a /dev/urandom eszközből olvassuk ki:
cat /dev/urandom | tr -dc 'a-zA-Z0-9' | head -c 256 > test3.txt

A példában létrehoztam egy 256 karakterből álló szöveges fájlt. Az adatforrás ebben az esetben is a /dev/urandom eszközünk volt, csak itt kiszűrtem néhány szöveges karakter tartományt (a-z, A-Z és 0-9), hogy kiírható legyen a tartalma a terminálban is, amit végül ki is irattam.
Így tehát most már van két újabb tesztfájlunk is, tehát folytathatjuk az md5sum parancs használatát immár bináris és szöveges próba fájlokkal is.
Egyszerre több ellenőrző összeget úgy helyezhetünk el egy md5 fájlban, hogy felsoroljuk a forrásfájlokat, végül átirányítjuk a kimenetét a lementeni kívánt fájlba:
md5sum test.txt test2.bin test3.txt > tests.md5
A példa kedvéért először csak simán kiirattam a parancs eredményét, amiben láthatjuk a három fájl ellenőrző összegét és a nevüket. Majd a fájlba mentés után kilistáztam a fájl tartalmát, amiben ugyanaz látható.
Ha nem egy időben szeretnénk tárolni ezeket, hanem mondjuk később kívánunk újabb fájl ellenőrző összeget tárolni, akkor a másik módszer a >> operátor használata:
md5sum test.txt >> tests.md5

Itt mégegyszer hozzáadtam a legelső fájlt, így jól látszik a hozzáfűzés.
Egyszerre több fájl ellenőrzése egy md5 fájl segítségével
Ha megvan az md5 fájlunk, amiben több ellenőrző összeg is szerepel, akkor futtassuk ugyanúgy az md5sum parancsot a -c kapcsolóval, mint korábban:
md5sum -c tests.md5

Sorban végigmegy a fájlban lévő tételeken, és ellenőrzi őket.
Megváltozott tartalmú fájl ellenőrzése
Nézzük meg hogy mi történik akkor, ha megváltozik valamelyik fájlunk tartalma. Például a nano program segítségével belemódosítok az egyik fájlba:
nano test3.txt

Itt belemódosítottam, és lementettem utána.
Majd ismét futtatom a korábbi ellenőrző md5sum parancsot:
md5sum -c tests.md5

Az md5sum parancs itt már kijelezte nekünk tételesen is, hogy "test3.txt: FAILED", valamint a művelet végén is kiír egy összegző figyelmeztetést arról, hogy hány eltérő fájlt talált.
Csak a hibás fájlok megjelenítése az ellenőrzés során
Ha nagyon hosszú az ellenőrzési listánk, tehát rengeteg fájlt kell időről időre ellenőriznünk, esetleg egy automatizált figyelési megoldást kell készítenünk, akkor a --quiet kapcsolóval elnyomhatjuk a hibátlan, azaz változatlan, eredeti fájlokra adott kimeneteket, és csak a hibák jelennek meg. Ehhez futtassuk az alábbi md5sum parancsot:
md5sum -c --quiet tests.md5

Így tehát csak a hibák jelennek meg, amit már egyszerűbben is fel tudunk dolgozni scriptjeinkben.
Fájl útvonalak kezelése
Eddig még nem esett szó a fájlok útvonalairól. A korábbi példák esetében a fájlok az aktuális munkakönyvtárban voltak, és azok ellenőrző összegeit generálta le az md5sum parancs, valamint ugyanezeknek a fájloknak is ellenőriztük az integritását is. Azonban ha automatizáltan szeretnénk ellenőrizni a különböző fájljaink integritását, akkor javasolt abszolút útvonalakat használni, hogy akárhonnan futtatható legyen az ellenőrző parancsunk vagy scriptünk.
Ebben a példában megnézzük, hogy milyen módokon adhatunk hozzá fájl ellenőrző összegeket az md5 összesítő fájlunkhoz. Az áttekinthetőség kedvéért három külön parancsban tekinthetjük meg a korábban már megismert >> hozzáfűzési operátor segítségével a fájlok hivatkozási módjait:
md5sum test.txt > tests.md5
md5sum ./test.txt >> tests.md5
md5sum /home/botond/test.txt >> tests.md5

A példában tehát három módon adtam hozzá ugyanahhoz az md5 fájlhoz a teszt fájlt:
- csak a fájlnév maga szerepel a hozzáadásban
- aktuális könyvtárral került megadásra a fájl
- abszolút útvonallal került hozzáfűzésre a fájl
Ezek közül az első kettő esetében nincs különbség, mindegyik az aktuális munkakönyvtárban keresi a fájlt, amikor majd ellenőrizzük, és a harmadik pedig abszolút elérése révén bárhonnan elérhető marad.
A fájlokat még ellenőriztem is ugyanebben a könyvtárban, ahol jól látszik, hogy az md5sum parancs értelmezte is a fájlnevek előtt megadott részeket is.
Lássuk mi történik, ha például kilépünk a gyökér könyvtárba és onnan próbáljuk lefuttatni a megadott fájlok integritásának ellenőrzését:
cd /
md5sum -c /home/botond/tests.md5
Itt természetesen magának az md5 fájlnak mindenképpen meg kell adni az elérését, mivel másik könyvtárból indítottuk az md5sum parancsot. De lássuk milyen kimenetet kaptunk:

md5sum: test.txt: No such file or directory test.txt: FAILED open or read md5sum: ./test.txt: No such file or directory ./test.txt: FAILED open or read /home/botond/test.txt: OK md5sum: WARNING: 2 listed files could not be read
Ahogy várható volt, az md5sum parancs elkezdte feldolgozni a fájlt, haladt sorban. Az első kettő fájltársítási tételt nem találta meg, a harmadikat viszont igen, és ott "OK" jelzést is adott.
Fájlok kiinduló összegzési értékeinek kötegelt felvitele egy md5 fájlba
Tegyük fel, hogy van egy összetettebb könyvtárstruktúránk, amiben sok fájl van, és ezeket szeretnénk időnként ellenőrizni, hogy változott-e a fájlok tartalma.
A példa kedvéért kicsit átrendeztem a "terepet", és bemásoltam a teszt fájlokat egy "test" nevű alkönyvtárba, ahol további alkönyvtárakba is bemásoltam a korábbi tesztfájlokat. A tree parancs segítségével most vizuálisan tehát így néz ki a könyvtárszerkezetünk:
tree test

test ├── a │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── b │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── c │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── d │ ├── test.txt │ ├── test2.bin │ └── test3.txt ├── test.txt ├── test2.bin └── test3.txt
A feladatunk tehát, hogy ezt a teljes könyvtárstruktúrát bejárjuk, és a benne lévő összes fájlnak legeneráltassuk az ellenőrző md5 összegét, és felvegyük az md5 fájlunkba. Ehhez a feladathoz például a find parancsot is használhatjuk:
find test -type f -exec md5sum {} + > tests.md5
A parancs paraméterei:
- -type f: Csak fájlokat keresünk
- -exec md5sum {}: futtatja az md5sum parancsot a talált fájlokon
- + : A + jel gondoskodik róla, hogy a find parancs által talált fájlokat összegyűjtse, és egy md5sum parancs futtatással hajtsa végre a teljes halmazt. így a parancs futtatása hatékony, mert nem kell minden fájlra külön lefuttatni az md5sum parancsot.
- > tests.md5: Ez pedig átirányítja az egész parancs kimenetét a megadott fájlba

Amint láthatjuk, bekerült az összes fájl. Viszont itt relatív útvonalakkal kerültek be. Ha abszolút útvonalakkal szeretnénk társítani az ellenőrző összegeket, akkor a find parancsnak is abszolút módon adjuk meg a könyvtárat:
find /home/botond/test -type f -exec md5sum {} + > tests.md5

Így tehát már pontosan meg vannak adva a fájlok, tehát bárhonnan ellenőrizhetők az md5 fájl segítségével a beállított fájlok:
cd /
md5sum -c /home/botond/tests.md5

Az abszolút útvonalak használatával biztosak lehetünk benne, hogy az md5sum parancs megtalál minden fájlt az ellenőrző fájlban.
Eredmények script-ekben történő felhasználása
Ha automatizáltan szeretnénk ellenőrizni a fájljaink eredetiségét, integritását, amit scriptből kell megoldanunk, akkor a --status kapcsoló nyújtja számunkra a megoldást.
Amikor az md5sum parancsot a --status kapcsolóval használjuk, a parancs nem ír ki semmilyen kimenetet a standard kimenetre (stdout), hanem csak az állapotkódot állítja be. Ez azt jelenti, hogy ha az ellenőrző összeg egyezik a fájlban szereplővel, az md5sum állapotkódja 0 lesz, ha pedig ellenőrzés során hiba történik (például az ellenőrző összeg nem egyezik, vagy a fájl nem elérhető), az md5sum állapotkódja 1 lesz.
Lássuk ezt egy újabb példával:
md5sum test.txt > tests.md5
md5sum -c tests.md5
md5sum -c --status tests.md5
echo $?
echo "modosit" >> /home/botond/test/test.txt
md5sum -c --status tests.md5
echo $?
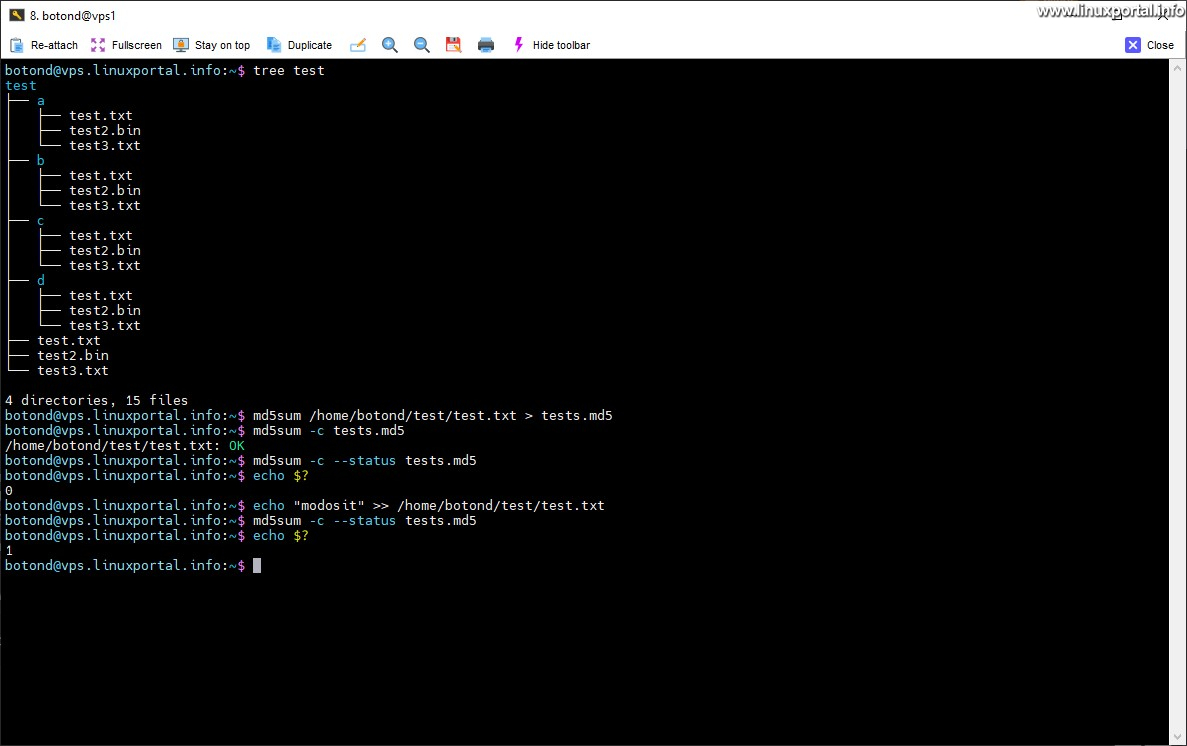
Itt a következő történik:
Először lekérdeztem a fájlstruktúrát, amiben kinéztem egy teszt fájlt. Ez esetben a test.txt fájlt használtam, itt abszolút eléréssel. Ebből készítettem egy új hash értéket, felülírva a korábbi tests.md5 fájlomat. Ezután vissza is ellenőriztem, minden rendben. Majd az md5sum parancs --status kapcsolóját használva ellenőriztem az állapotkódot, amit echo-val irattam ki.
Ezután beleírtam egy "modosit" szót a teszt fájlba, hogy megváltozzon annak a tartalma. Ezután ismét lekértem az állapotkódját a hash értéknek, és kiirattam. Itt már 1-et adott vissza.
Így tehát ha script-eket használunk nem kell az md5sum parancs esetén sem különböző szöveges kimeneteket feldolgoznunk, hanem a --status kapcsoló segítségével rávehetjük, hogy az állapotkódban adja nekünk vissza az eredményt, amit már kényelmesen fel tudunk dolgozni bármilyen shell scriptben, például:
md5sum -c --status tests.md5
if [ $? -eq 0 ]; then
echo "Az ellenőrzés sikeres, a fájl nem változott."
else
echo "A fájl tartalma megváltozott, vagy az ellenőrzés sikertelen volt."
fi
Bináris és szöveges módú fájlbeolvasás
Az md5sum parancs lehetőséget biztosít a fájlok bináris vagy szöveges módú beolvasásának explicit módon történő megadására. Ennek a résznek inkább elméleti vonzata van, így megemlítjük ennek is az okát pár mondatban.
a parancsnak explicit módon a bináris beolvasást a -b, --binary kapcsolóval, míg a szöveges beolvasási módot pedig a -t, --text kapcsolóval adhatjuk meg.
A szöveges mód esetében, ha az md5sum parancsot Windows operációs rendszeren használják, a program a fájl végén lévő CR+LF (Carriage Return + Line Feed, \r\n) karakterkombinációt egyetlen LF (Line Feed, \n) karakterre konvertálja, mivel a Windows rendszerek a sorvégeket CR+LF párosként jelölik, míg a Linux és Unix-szerű POSIX rendszerek csak LF-et használnak. Ez a konverzió segít abban, hogy a fájlok hash értékei platformok között konzisztensek maradjanak, figyelembe véve a különböző sorvégezési konvenciókat.
Bináris mód
A bináris mód esetében az md5sum nem hajt végre semmilyen konverziót a sorvége karaktereken, és pontosan úgy olvassa be a fájlt, ahogy az van. Ez azt jelenti, hogy a CR+LF kombinációk is megmaradnak Windows rendszeren generált fájlok esetében, ami eltérő hash értéket eredményezhet, ha ugyanazt a fájlt különböző operációs rendszereken használva hasonlítják össze.
Hogyan adható meg a mód
Linux és Unix-szerű rendszerek esetében általában nincs szükség explicit mód megadására, mivel ezek a rendszerek konzisztensen LF-et használnak sorvégeként, és az md5sum alapértelmezés szerint bináris módban fut. Windows esetében azonban az md5sum implementációtól függően lehetőség van explicit mód választására, ha ez szükséges az adott feladathoz.
A lényeg, hogy a bináris és szöveges mód közötti különbség az újsor karakterek kezelésében van, ami Windows rendszereken befolyásolhatja a fájlok MD5 hash értékének kiszámítását. A választott mód határozhatja meg, hogy a generált hash értékek platformok között konzisztensek lesznek-e, különösen ha a fájlok Windows és Unix/Linux rendszerek között kerülnek átvitelre.
Konklúzió
Az md5sum parancs segítségével egyszerűen és hatékonyan ellenőrizhetjük fájljaink integritását. Könnyen összehasonlíthatunk fájl változatokat, például tőlünk kikerült (és később visszatért) fájlok eredetiségét, vagy ellenőrző összegeket biztosíthatunk letöltésre kínált fájljainkhoz, hogy a felhasználóink is ellenőrizhessék azokat, ha más forrásból jutottak a fájlokhoz, vagy akár figyelhetjük például a webszerverünkön rendszeresen megújításra kerülő Let's Encrypt tanúsítványainkat is, amiknek ha megváltozik a tartalmuk, futtathatunk saját scripteket, stb Az md5sum parancs felhasználási területe tehát széleskörű, és használata igen egyszerű. Még akár a Debian 11-ből eltávolított Incron szolgáltatás is részben kiváltható vele, persze nem kapunk valós idejű figyelést cron-ból futtatva, de olyan helyeken kiválóan alkalmazható, ahol nem létszükséglet a valós idejű fájlmegfigyelés, stb.
- A hozzászóláshoz regisztráció és bejelentkezés szükséges
- 84 megtekintés